







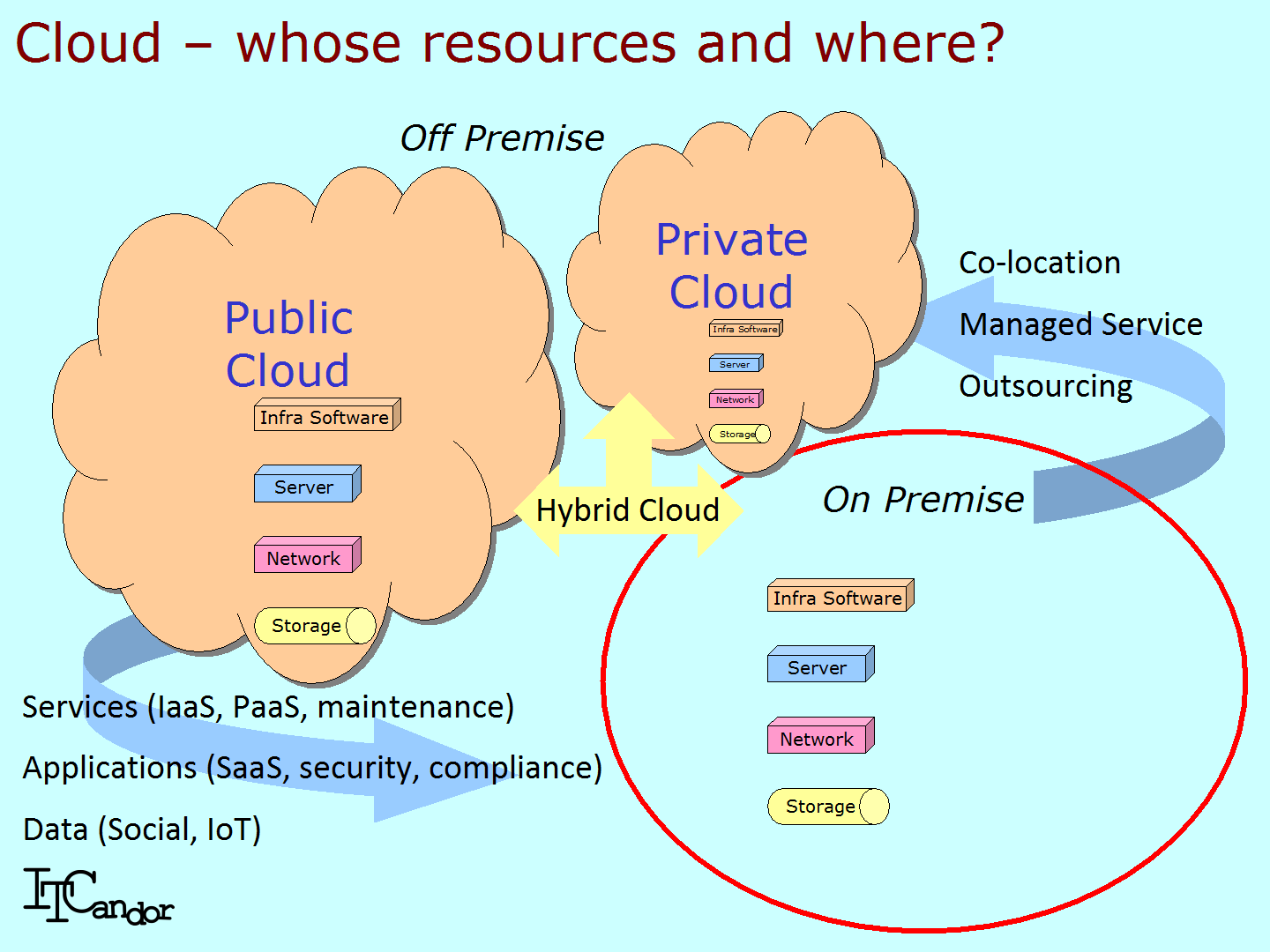
Over the last few years I’ve extensively about cloud computing and – as a researcher – spent a lot of time trying to define it enough to size and forecast its growth. It’s the right time to look at it again. In this post I’ll look at its adoption as well as defining it by what it is (and importantly) is not. The Figure above shows enterprise computing in medium/large organisations which typically has run their own IT services from data centres. Their IT departments are service providers of applications to a variety of users including internal general purpose and specialist employees, as well as external customers and suppliers. Traditionally these services stem from software running on servers, storage and network devices – an infrastructure of resources owned by the organisation and run ‘on premise’ in its own data centre.
{kind=link}
In fact very few organisations have ever owned all of the computer equipment they use: just as general outsourcing starts with the car park and canteen, so suppliers have been providing a wide set of services (the top right of my Figure) – from complete outsourcing (buying and running the data centre before consolidating these activities with others)… to managed services of all sorts (typically a smaller subset of full outsourcing)… to providing co-location facilities for those customers who no longer want and/or have no long-term budget for a new-build data centre. We can also add such services as hardware and software maintenance, implementation and consulting. These – shall we say ‘traditional’ – services predated the cloud and usually continue to involve providing physical support. Many of these were adequately profitable for their suppliers, but expensive and inflexible for users: much of which might be improved by adopting cloud services.
 As cloud computing is considered a modern and positive term so users have embraced it to refer to their own data centers. While it’s possible to argue that cloud computing must involve some level of virtualisation, a service catalogue and other features to distinguish it from older styles of computing, many organisations now refer to all of their IT resources as a ‘private cloud’ rather than a ‘traditional data center’ and if you’re not dong that already I’d highly recommend it. In this context it’s irrelevant that some suppliers think of themselves as ‘cloud builders’ (especially those who do not offer their own IaaS or PaaS services) – what else would they be doing if they weren’t helping customers to deliver virtualised applications?
As cloud computing is considered a modern and positive term so users have embraced it to refer to their own data centers. While it’s possible to argue that cloud computing must involve some level of virtualisation, a service catalogue and other features to distinguish it from older styles of computing, many organisations now refer to all of their IT resources as a ‘private cloud’ rather than a ‘traditional data center’ and if you’re not dong that already I’d highly recommend it. In this context it’s irrelevant that some suppliers think of themselves as ‘cloud builders’ (especially those who do not offer their own IaaS or PaaS services) – what else would they be doing if they weren’t helping customers to deliver virtualised applications?
Public clouds (top left of the Figure) also use servers, storage, networking and infrastructure resources: the largest ones (Amazon, IBM, Google, eBay, Alibaba, etc.) take on the role of Original Design Manufacturer (ODM – see our Acronym Buster for a list of common terms) in which they take large numbers of components (Intel Xeon chips, Seagate and Western Digital disk drives, and/or Micron NAND and DRAM chips for instance) to build massive scale-out systems from which to provide their services. If cloud is going to be cheaper than traditional computing for users the discount these large vendors can negotiate for components, the efficiency of how they run things and the scale they can achieve are paramount. When adopting Iaas, PaaS and/or SaaS customers need to look beyond the comparative costs of build a new data center and the advantages of Op Ex over Cap Ex towards increased network costs, application vulnerability in case of a supplier failure,, currency fluctuation if the supplier is in another country and/or charges in a different currency (typically dollars) and trusting someone else to look after their data – all of which are often overlooked in the marketing of cloud.
While there are many types of third party data (see bottom right in my Figure) from social media feeds to IoT information from other organisations’ sensors, trusting someone else to look after your own data is a big step. This is why many medium and large organisations go no further than putting their data in a private – rather than public – cloud. It’s not just a matter of trust: legislative compliance often demands that you have this in your own control and subject to audits. Some legislation such as PCI compliance for credit card transactions weren’t written for virtualised systems – let alone clouds.
 When new cloud services replace internal applications you’ll need to think about who ‘consumes’ them – as they will typically be departments or others who were previously your internal customers. I’ve written before about the politics of converged infrastructure – the same holds true of cloud computing. To mitigate the risks of ‘shadow IT’ you need to develop some central control of the service catalogue, for which the starting point is usually the adoption of a reference architecture – see my description of IBM‘s and HPE‘s. Most organisations will end up with a ‘hybrid’ cloud model, which is a combination of internal, private and public resources, which brings me neatly back to the theme of this post – cloud computing is about who owns the resources (you or a supplier) and where they are located (on or off premise). Understanding this and tracking the sales of the various elements is an essential role for a modern research company – something ITCandor does rather well.
When new cloud services replace internal applications you’ll need to think about who ‘consumes’ them – as they will typically be departments or others who were previously your internal customers. I’ve written before about the politics of converged infrastructure – the same holds true of cloud computing. To mitigate the risks of ‘shadow IT’ you need to develop some central control of the service catalogue, for which the starting point is usually the adoption of a reference architecture – see my description of IBM‘s and HPE‘s. Most organisations will end up with a ‘hybrid’ cloud model, which is a combination of internal, private and public resources, which brings me neatly back to the theme of this post – cloud computing is about who owns the resources (you or a supplier) and where they are located (on or off premise). Understanding this and tracking the sales of the various elements is an essential role for a modern research company – something ITCandor does rather well.